

简介
当前,我国已经进入大数据时代,在这样的时代背景下,以Hadoop和Spark为基础的大数据应用也逐渐深入,正在从互联网企业,逐渐拓展到电信,金融,政府,医疗这些传统行业。目前Hadoop和Spark应用场景已广泛应用于日志存储、查询和非结构化数据处理等大数据应用领域,随着Hadoop和Spark技术的不断成熟以及生态系统相关产品的完善,包括Hadoop和Spark对SQL不断加强的支持,以及主流商业软件厂商对Hadoop和Spark支持的不断增强,必定会带动Hadoop和Spark渗透到越来越多的应用场景中。2015年是中国大数据的应用落地年,越来越多的行业用户开始重视并启动大数据相关的项目。而在大数据领域的众多技术中,最受关注的是衍生于开源平台的Hadoop和Spark生态系统。Hadoop从2006年诞生至今已经超10年时间。2015年,整个生态系统变得比以往更加丰富,无论是在开源领域,商业软件厂商或是硬件厂商,都开始推出基于Hadoop的相关产品。Hadoop之所以受到如此的关注,主要原因在于它支持用户在低价的通用硬件平台上实现对大数据集的处理和分析,在某种程度上替代了传统数据处理所需的昂贵的硬件设备和商业软件。本课程将分别从理论基础知识,程序设计以及应用案例(数据挖掘和机器学习)三方面对以Hadoop为基础的大数据知识记性介绍。本课程采用循序渐进的课程讲授方法,首先讲解Hadoop和Spark系统基础知识,概念及架构,之后讲解Hadoop和Spark实战技巧,最后详尽地介绍Hadoop和Spark经典案例(数据挖掘和机器学习),使培训者从概念到实战,均会有收获和提高。
目标
1.本课程将为大家全面而又深入的介绍Hadoop和Spark平台的构建流程,涉及Hadoop和Spark系统基础知识,概念及架构,Hadoop和Spark实战技巧(数据挖掘和机器学习),Hadoop和Spark经典案例等。
2.通过本课程实践,帮助学员对Hadoop生态系统有一个清晰明了的认识;
3.理解Hadoop系统适用的场景;
4.掌握Hadoop等初中级应用开发技能;
5.搭建稳定可靠的Hadoop集群,满足生产环境的标准;
6.掌握如何应用hadoop和spark完成数据挖掘和机器学习任务;
7.了解和清楚大数据应用的几个行业中的经典案例。
课程时长
2天(12H)
受众人群
各类 IT/软件企业和研发机构的软件架构师、软件设计师、程序员。对于怀有设计疑问和问题,需要梳理解答的团队和个人,效果最佳。
学员基础
学员学习本课程应具备下列基础知识:1)了解Java语言;2)了解Linux系统;3)数据挖掘基础
分享提纲
| 时间 | 主题 | 授课内容 |
第一天 大数据架构 (偏重基础架构讲解) | 大数据架构概述 | 1.大数据层级结构 介绍大数据系统基本架构与流程 2.Hadoop生态系统概述以及版本演化 概要介绍Hadoop生态系统及其版本演化历史,并给出hadoop版本选择建议 3.Spark生态系统概述 概要介绍Spark生态系统及其特点,并与Hadoop对比 |
| 数据收集系统Flume与Sqoop | 介绍如何使用flume和sqoop两个系统将外部流式数据(比如网站日志,用户行为数据等)、关系型数据库(比如MySQL、Oracle等)中的数据导入Hadoop中进行分析和挖掘 | |
| 大数据存储系统HDFS与HBase | 1.HDFS 2.0 原理、特性与基本架构 2.理论:介绍HDFS 2.0原理与架构,以及使用方式 3.HBase原理,基本架构与案例分析 4.理论:介绍HBase应用场景、原理和架构,介绍几个HBase典型应用案例,包括互联网应用案例和银行应用案例 | |
| 分布式计算技术MapReduce与Hive | 1.介绍计算框架MapReduce基本原理,架构及程序设计方式 2.动手编写第一个MapReduce程序 3.Hive基本原理及使用方式 | |
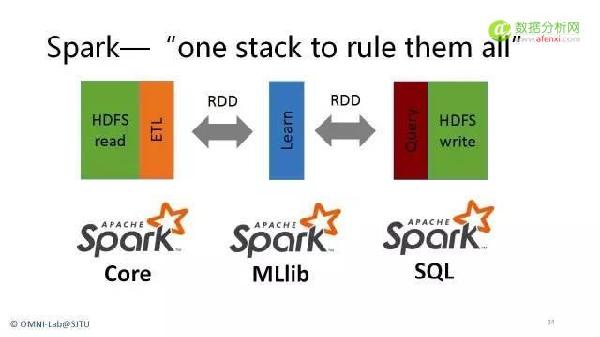
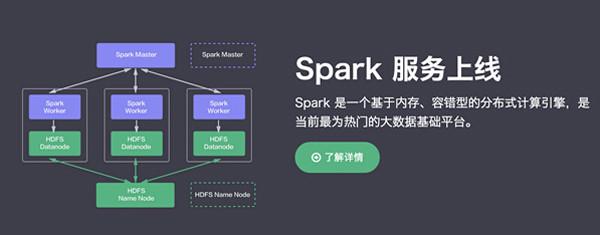
| 分布式计算技术Spark | 1.介绍计算框架Spark基本原理,架构及程序设计方式 2.Spark程序设计 | |
| 数据挖掘与机器学习 | 1.常见的数据挖掘与机器学习算法 2.Hadoop数据挖掘库mahout 3.Spark数据挖掘库mllib | |
第二天 大数据应用 (偏重架构和算法的应用) | 应用案例1:基于Hadoop的构建数据仓库 | 1.数据仓库基础介绍 2.如何利用大数据系统构建数据仓库 使用Flume+HDFS+MapReduce+Hive构建数据仓库 3.数据仓库基本架构 4.数据仓库应用 如报表生成 |
| 应用案例2:用户画像系统 | 1.什么是用户画像系统 2.如何构建用户画像系统 使用Flume/sqoop+HDFS+HBase+MapReduce/Spark+redis构建用户标签系统 3.用数据挖掘方式构建用户标签 应用逻辑回归、聚类、分类等机器学习和数据挖掘算法构建用户标签 4.用户画像系统应用 用户画像系统在用户信用等级分级、大数据营销中、用户流失预警、潜在用户分析、异常检测与分析等方面的应用 | |
| 应用案例3:商品推荐系统 | 1.什么是商品推荐系统 2.商品推荐系统基本架构 使用Flume+HDFS +Spark+Redis构建推荐系统 3.推荐算法 推荐算法详解 | |
| 应用案例4:数据挖掘系统 | 1.什么是数据挖掘系统 2.数据挖掘算法的使用 以Spark为主,如何设计和实现逻辑回归、聚类、分类等机器学习和数据挖掘算法 3.数据挖掘的典型应用 |

Semon Dong
百林哲咨询(北京)有限公司专家团队成员

Semon Dong
百林哲咨询(北京)有限公司专家团队成员
Semon Dong
百林哲咨询(北京)有限公司专家团队成员

Semon Dong
百林哲咨询(北京)有限公司专家团队成员
Semon Dong
百林哲咨询(北京)有限公司专家团队成员

Semon Dong
百林哲咨询(北京)有限公司专家团队成员
Semon Dong
百林哲咨询(北京)有限公司专家团队成员




 京ICP备2022035414号-1
京ICP备2022035414号-1
