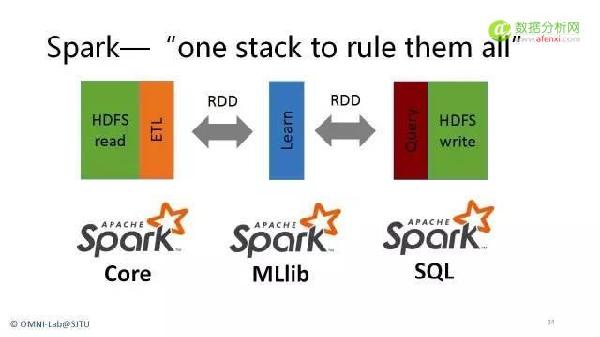

简介
当下是大数据时代,为构建大数据平台,技术人员需要对分布式计算平台有一定深入的理解和应用 。MapReduce作为一个经典 的分布式计算框架,已经广为人知,且得到了广泛的应用,但MapReduce自身存在很多问题,包括迭代式计算和DAG计算等类型的数据挖掘与机器学习算法性能低下,不能很好地利用内存资源,编程复杂度较高等。为了克服MapReduce的众多问题,新型计算框架Spark出现了。Spark被认为是新一代内存性计算框架,未来之星,Spark官方统计,Spark运行效率比MapReduce快10~100倍,下图是一个简单对比图(逻辑回归算法,横轴是迭代轮数,纵轴是所用时间):倍,下图是一个简单对比图(逻辑回归算法,横轴是迭代轮数,纵轴是所用时间):
2014年,Spark已经被不少互联网公司采用,大部分数据挖掘算法和迭代式算法在逐步从MapReduce平台迁移到Spark平台中,包括 阿里巴巴(广告系统),腾讯(广点通精准推荐),百度,优酷土豆,360,支付宝等互联网公司已经在线上产品中使用spark,且取得了令人满意的效果,另外,部分省份的运营商也正在尝试使用spark解决数据挖掘和分析问题,部分银行,如工商银行,也正在尝试spark平台。据不完全统计,2015年,大部分互联网公司,运营商和金融公司(这里指已经在使用hadoop的公司),均会考虑和尝试引入spark平台,以部分替代MapReduce为主的低效的批处理计算平台。本课程将分别从理论基础知识,系统搭建以及应用案例三方面对spark进行介绍。本课程采用循序渐进的课程讲授方法,首先讲解Spark系统基础知识,概念及架构,之后讲解Spark实战技巧,最后详尽地介绍Spark经典案例,使培训者从概念到实战,均会有收获和提高。
目标
1.本课程将为大家全面而又深入的介绍Spark平台的构建流程,涉及Spark系统基础知识,概念及架构, Spark实战技巧,Spark经典案例等。
2.通过本课程实践,帮助学员对Spark生态系统有一个清晰明了的认识;理解Spark系统适用的场景;掌握Spark等初 中级应用开发技能;搭建稳定可靠的Spark集群,满足生产环境的标准;了解和清楚大数据应用的几个行业中的经典案例,包括阿里巴巴,腾讯,百度等互联网行业,中国移动和联通等运营商。
课程时长
3天(18H)
受众人群
各类IT/软件企业和研发机构的软件架构师、软件设计师、程序员。对于怀有设计疑问和问题,需要梳理解答的团队和个人,效果最佳。
学员基础
学员学习本课程应具备下列基础知识:
1)了解Java语言(Scala语言会作为课程内容进行介绍);
2)了解Linux系统;
基于Spark的大数据处理案例介绍
1.电子商务商品推荐系统
基于spark的商品推荐系统是互联网领域对spark的一个经典应用,阿里巴巴,京东,中国移动等大型公司都进行了广泛的应用,效果 显著,商品推荐系统通常包含基于规则的商品推荐和基于模型的商品推荐两类,分别介绍如下:
(1)基于规则的广告推荐
举例:筛选出北京地区,年龄在18~25岁的女士,并发布某广告
(2)基于模型的广告推荐
比如逻辑回归:
输入:性别,年龄,点击和购买记录
输出:是否会购买商品X
典型架构图如下:

2.大数据精准推荐
(1)腾讯
广点通是最早使用Spark的应用之一。腾讯大数据精准推荐借助Spark快速迭代的优势,围绕“数据+算法+系统”这套技术方案,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上,支持每天上百亿的请求量。
基于日志数据的快速查询系统业务构建于Spark之上的Shark,利用其快速查询以及内存表等优势,承担了日志数据的即席查询工作。在性能方面,普遍比Hive高2-10倍,如果使用内存表的功能,性能将会比Hive快百倍。
腾讯的广点通是以hadoop和spark为内核构建的,其架构如下:

(2)阿里巴巴
阿里搜索和广告业务,最初使用Mahout或者自己写的MapReduce来解决复杂的机器学习,导致效率低而且代码不易维护。淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等。将Spark运用于淘宝的推荐相关算法上,同时还利用Graphx解决了许多生产问题,包括以下计算场景:基于度分布的中枢节点发现、基于最大连通图的社区发现、基于三角形计数的关系衡量、基于随机游走的用户属性传播等。
3.某运营商基于spark的大数据架构
混搭架构是当前运营商的自然选择,根据数据的热度和存储成本来分布。通过三者的有效融合,以提供最大的计算能力。一般采用的思路为:
1、采用Tableau作为图形化配置和管理工具,将ETL过程、原子处理等转化为Spark的Task
2、离线批量接口和实时接口采用同样的配置,只有处理的时间间隔属性不同
架构图如下所示:

分享提纲
| 时间 | 主题 | 授课内容 |
第一天: Spark基本概念与安装部署 | Spark大数据架构概述及案例简介 | 1.介绍Spark大数据层级架构及各层软件设计要求,包括数据收集,大数据存储,大数据计算框架,大数据应用等 2.Hadoop与Spark区别与联系 3.介绍Hadoop与Spark区别,关系以及定位。 4.Spark生态系统概述以及版本演化 5.概要介绍Spark生态系统及其版本演化历史,并给出spark版本选择建议 |
| Spark产生动机与基本概念 | 1.Spark产生背景 介绍Spark产生的背景,与MapReduce对比,其优缺点是什么 2.Spark核心概念 2.1RDD 2.2基本操作:transformation与 action 3.Spark程序架构 3.1Driver/executor 3.2容错机制 | |
| Spark安装部署 | 1.Spark运行模式简介 1.1standlone模式 1.2Spark on yarn模式 2.搭建一个spark on yarn集群 3.搭建yarn集群 4.运行第一个spark程序 | |
第二天: Spark程序设计、内部原理与案例分析 | Spark程序设计实例 | 1.Scala语言基础 2.介绍scala语言,常用语法以及库函数 3.Spark程序设计方法 4.Spark程序基本构成 5.SparkContext,RDD,transformation/action 6.Spark API介绍 7.如何创建RDD(scala集合,HDFS文件,HBase文件等) 8.如何基于RDD进行数据处理,介绍常见的分布式算子 9.如何保存处理结果(返回到driver端,写入hdfs等) 10.广播变量与累加器 11.Spark程序设计实例 12.分布式Pi估算程序 13.K-means分类算法实现 14.逻辑回归算法实现 |
| Spark内部原理 | 1.Spark程序运行流程概述 介绍Spark从提交,到调度,到最后执行完成整个过程 2.Spark内部执行流程 介绍Spark程序内部的逻辑查询计划,物理查询计划,调度等几个环节 3.Spark shuffle实现 介绍Spark shuffle发展史及实现逻辑 4.Spark算子的内部机制 以reduceByKey和groupByKey两个算子为例介绍spark算子的内部实现原理 | |
| Spark与外部系统整合 | 1.Spark与Kafka和flume结合 介绍如何使用kafka和flume将数据导入hadoop中,以便使用spark处理 2.Spark与Storm结合 介绍如何使用spark实时处理数据 3.Spark与HBase和HDFS结合 介绍Spark如何与HBase和HDFS实现数据的读写交互 4.Spark与关系型数据库和hive结合 介绍如何使用spark与关系型数据库和hive结合 | |
| Spark调优方法 | 1.Spark调优思想 2.spark调优方法 | |
| Spark案例分析 | 1.介绍一个经典的Spark应用案例:基于Spark的商品推荐系统,内容包括: 1.1项目背景 1.2项目架构 1.3项目实施 | |
第三天: Spark生态系统 | Spark SQL | 1.Spark SQL定位 2.如何使用SparkSQL处理数据 2.1使用SparkSQL处理HDFS上数据 2.2使用SparkSQL处理Hive中的数据 3.Spark SQL与Spark及Spark Streaming结合 |
| MLlib | 1.介绍Spark的数据挖掘库MLlib,重点介绍其内部的几个分类算法,聚类算法和推荐算法,包括逻辑回归,K-Means,协同过滤等 | |
| GraphX | 1.介绍Spark内部的图计算框架GraphX,重点介绍它的基本原理及使用方法 |

Semon Dong
百林哲咨询(北京)有限公司专家团队成员

Semon Dong
百林哲咨询(北京)有限公司专家团队成员

Semon Dong
百林哲咨询(北京)有限公司专家团队成员

Semon Dong
百林哲咨询(北京)有限公司专家团队成员
Semon Dong
百林哲咨询(北京)有限公司专家团队成员

Semon Dong
百林哲咨询(北京)有限公司专家团队成员
Semon Dong
百林哲咨询(北京)有限公司专家团队成员




 京ICP备2022035414号-1
京ICP备2022035414号-1
