

简介
当前,我国已经进入大数据时代,在这样的时代背景下,Hadoop/Spark的应用也逐渐深入,正在从互联网企业,逐渐拓展到电信,金融,政府,医疗这些传统行业。目前Hadoop/Spark应用场景已广泛应用于日志存储、查询和非结构化数据处理等大数据应用领域,随着Hadoop/Spark技术的不断成熟以及生态系统相关产品的完善,包括Hadoop/Spark对SQL不断加强的支持,以及主流商业软件厂商对Hadoop/Spark支持的不断增强,必定会带动Hadoop/Spark 渗透到越来越多的应用场景中。2014年是中国大数据的应用落地年,越来越多的行业用户开始重视并启动大数据相关的项目。而在大数据领域的众多技术中,最受关注的是衍生于开源平台的Hadoop/Spark 生态系统。Hadoop/Spark 从2006 年诞生至今已经超8年时间。2014 年,整个生态系统变得比以往更加丰富,无论是在开源领域,商业软件厂商或是硬件厂商,都开始推出基于Hadoop /Spark的相关产品。Hadoop之所以受到如此的关注,主要原因在于它支持用户在低价的通用硬件平台上实现对大数据集的处理和分析,在某种程度上替代了传统数据处理所需的昂贵的硬件设备和商业软件。本课程将分别从理论基础知识,系统搭建以及应用案例三方面对Hadoop/Spark进行介绍。本课程采用循序渐进的课程讲授方法,首先讲解Hadoop/Spark系统基础知识,概念及架构,之后讲解Hadoop/Spark实战技巧,最后详尽地介绍Hadoop/Spark经典案例,使培训者从概念到实战,均会有收获和提高。
1)了解Java语言(Scala语言会作为课程内容进行介绍);
2)了解Linux系统.
课程时长
2天(12H)
分享提纲
| 时间 | 主题 | 授课内容 |
第一天:Hadoop大数据分布式体系与框架 | 大数据架构基础 | 1.大数据分布式理论体系介绍大数据理论体系,设计大数据分布式基本构成,层次化架构等 2.大数据开源实现框架Hadoop与Spark介绍主流的大数据基础框架Hadoop和Spark,涉及他们的基本构成以及层次关系等。(涉及到的系统,数据收集层:Flume/Sqoop/Kafka,数据存储层:HDFS/HBase,资源管理层:YARN,计算引擎层:MapReduce/Saprk/Storm/Spark Streaming,数据分析层:Hive) 3.大数据分布式架构应用案例主要从应用背景和架构上进行介绍,另外一讲会更加详细介绍。 3.1分布式日志收集和处理系统 3.2互联网电子商务推荐系统 |
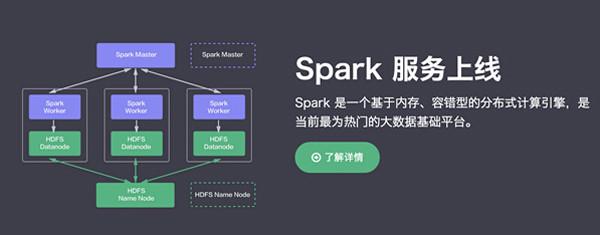
| Hadoop大数据架构关键组件讲解 | 1.分布式批处理(Batch)架构 1.1数据收集系统Flume重点介绍Flume架构以及使用经验 1.2分布式存储系统HDFS和HBase重点介绍HDFS和HBase架构以及实际应用经验,其中HBase将介绍两个经典案例:使用HBase构建时间序列数据库和阿里在历史账单查询方面的应用。 1.3分布式计算引擎MapReduce与Spark重点介绍MapReduce与Spark的不同,以及技术选型和应用经验 1.4数据分析系统Hive重点介绍Hive On MR/Tez,以及如何使用Hive构建数据仓库 2.分布式流式/实时处理(Streaming)架构 2.1分布式消息队列Kafka重点介绍Kafka架构以及应用经验 2.2流式计算框架Storm重点介绍Storm架构以及应用经验,以及应用案例(构建实时推荐模块) 3.Hadoop大数据系统的监控和运维介绍如何高效地监控和运维一整套大数据系统 | |
| Hadoop大数据架构在互联网中应用 | 3.1 案例1:分布式日志收集和处理系统 3.2 案例2:互联网电子商务推荐系统 结合上一部分的组件讲解,进一步介绍这两个典型案例 | |
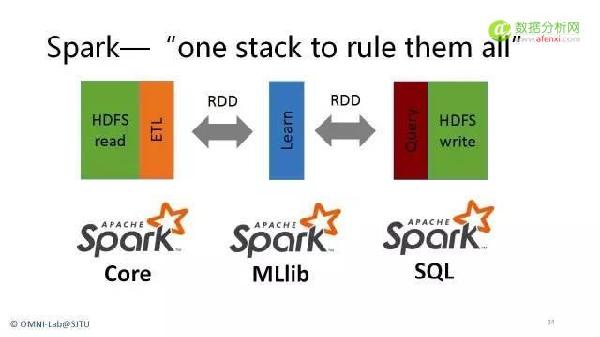
第二天:分布式内存计算框架Spark | Spark基础 | 1.park基础 1.1Spark产生原因以及优势(与MapReduce对比) 1.2Spark基本概念(RDD/cache/ transformation/action) 1.3Spark程序构成以及运行模式 1.4spark程序构成,以及常见的运行模式(本地模式,分布式模式) 2.Spark程序设计实例 2.1Spark程序设计基础 2.1.1如何创建RDD(scala集合,HDFS文件,HBase文件等) 2.1.2如何基于RDD进行数据处理,介绍常见的分布式算子 2.1.3如何保存处理结果(返回到driver端,写入hdfs等) 2.1.4广播变量与累加器 2.2Spark程序设计实例 2.2.1分布式Pi估算程序 2.2.2K-means分类算法实现 2.2.3逻辑回归算法实现 |
| Spark内部原理剖析(下午) | 1.Spark程序运行流程概述介绍Spark从提交,到调度,到最后执行完成整个过程 2.Spark内部执行流程介绍Spark程序内部的逻辑查询计划,物理查询计划,调度等几个环节 3.Spark shuffle实现介绍Spark shuffle发展史及实现逻辑 4.Spark算子的内部机制以reduceByKey和groupByKey两个算子为例介绍spark算子的内部实现原理 | |
| Spark调优方法(下午) | 1.Spark调优思想 2.spark调优方法 | |
| Spark生态系统(下午) | 1.流式计算框架Spark Streaming背景,基本原理以及应用介绍Spark Streaming基础,涉及产生背景(与Storm对比),基本原理以及应用场景。 2.分布式SQL引擎SparkSQL基本原理和应用 3.分布式数据挖掘库MLlib,,重点介绍其内部的几个分类算法,聚类算法和推荐算法,包括逻辑回归,K-Means,协同过滤等 4.Spark应用案例:Spark在电子商务系统中的应用 | |
| Spark应用案例 | 1.用户画像系统 |

Semon Dong
百林哲咨询(北京)有限公司专家团队成员

Semon Dong
百林哲咨询(北京)有限公司专家团队成员

Semon Dong
百林哲咨询(北京)有限公司专家团队成员
Semon Dong
百林哲咨询(北京)有限公司专家团队成员
Semon Dong
百林哲咨询(北京)有限公司专家团队成员

Semon Dong
百林哲咨询(北京)有限公司专家团队成员
Semon Dong
百林哲咨询(北京)有限公司专家团队成员




 京ICP备2022035414号-1
京ICP备2022035414号-1
