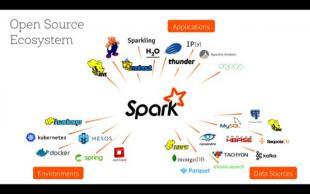

简介
Spark是继MapReduce之后新一代的大数据计算框架,相比MapReduce框架其具有可伸缩、基于内存计算等特点,以及可以直接读写HDFS上数据等优势,在进行批处理时更加高效,并有更低的延迟,已经成为轻量级大数据快速处理的统一平台。此外,Spark平台集成了Spark SQL、Spark Streaming、MLlib、GraphX、SparkR等模块,可以提供一站式解决方案,让从业者的工作变得越来越便捷。
课程特点/亮点
理论与案例相结合,循序渐进的阐述Spark平台的原理和使用方案。
目标
该课程使学员:
了解Spark平台的特性和优势;
掌握Spark平台架构和个组件的功能;
掌握利用Spark进行数据分析的基本方法;
掌握利用Spark进行数据挖掘/机器学习的基本方法;
学习基于Spark平台构建大数据项目的实际案例。
课程时长
1天(6H)
受众人群
大数据开发人员、大数据运维人员、大数据科学家、算法研究者及系统架构师等
分享提纲
| 1. Spark简介 | 1.1 Spark平台架构 1.2 Spark特点 1.3 Spark与MapReduce对比 1.4 Spark应用场景 1.5 Spark重要组件介绍 1.5.1 SparkSQL介绍 1.5.2 SparkStreaming介绍 1.5.3 Spark MLLib介绍 1.5.4 SparkGraphX介绍 |
2. Spark平台部署 和作业提交 | 2.1 Local模式 2.2 Standalone模式 2.3 Yarn模式 2.4 部署和作业提交参数详解 |
| 3. 编程模型 | 3.1RDD介绍 3.2创建RDD 3.3RDD基本操作 3.4共享变量 3.5累加器 |
| 4. 外部数据源的存取 | 4.1文件格式 4.2文件系统 4.3结构化数据 4.4数据库连接 |
| 5. SparkSQL | 5.1SparkSQL概述 5.2在应用中使用SparkSQL 5.3 HiveContext介绍 5.4 SparkSQL与Hive对比 5.5 Thrift JDBC/ODBC服务 5.6 SparkSQL与BI工具的整合 5.7SparkSQL调优 |
| 6. SparkMLLib | 6.1 机器学习概述 6.2 Spark MLLib介绍 6.3 Spark MLLib算法库 6.4 MLLib实例 |
| 7. Spark GraphX | 7.1 GraphX概述 7.2 GraphX编程接口 7.3 Pregel框架介绍 7.4 GraphX实例 |
| 8. Spark作业调优 | 8.1 重要参数配置 8.2关键性能考量 |




 京ICP备2022035414号-1
京ICP备2022035414号-1