

简介
1、Hadoop 产生的背景、发展历程及未来演进方向
1)Hadoop 是在什么背景下产生的,与传统的系统相比有哪些优势及劣势;
2)Hadoop 的发展历程,经历了哪些发展阶段,在各个发展阶段主要进行了哪些优化,解决了什么问题;
3)未来 Hadoop 将向什么方向发展,目前存在哪些问题需要在发展中解决;
2、对 hadoop 生态圈现状的全面介绍;
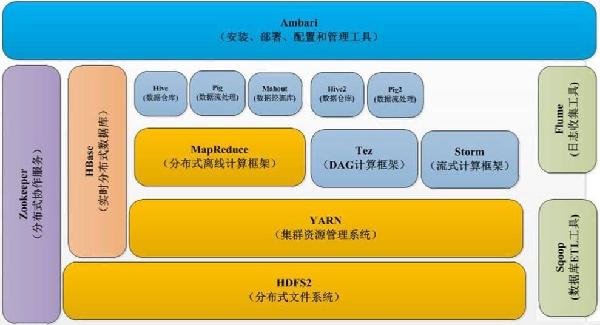
1)Hadoop 生态圈的参与者及所处的位置及作用;
2)国内企业在 Hadoop 生态圈的参与情况,参与的角色、成果及地位;
3、对 Hadoop 关键组件的作用、原理的全面介绍;
1)Hadoop 概况:基本框架、版本差异、在云计算及大数据的位置和关系
2)HDFS:原理、基本结构、副本存放策略、
3)Map Reduce 工作原理、算法原理及优化思想;
4)Yarn 原理,与 Hadoop1.0 在功能方面的改善点;
5)Name Node/Secondary Name Node 及 Date Node 详解;
6)Job Tracker 及 Task Tracker 详解;
7)Hbase 的作用、原理、结构;
8)Hive 的作用、原理,与传统数据仓库的相比的优劣势及协作关系;
9)Spark 原理、架构及运行模式;
10)Sqoop 和 Flume 作用、原理;
4、Hadoop 集群规划、部署及维护
1)集群规划步骤及规划要点:
2)Hadoop 安装及部署:系统模块组件介绍、部署结构、安装依赖关系等;
3)hadoop 维护及管理:
5、国内在 Hadoop 研究、实际使用及人才储备方面的情况
1)国内企业在 Hadoop 研究方面的参与情况,参与的角色、成果及地位;
2)国内企事业单位在 Hadoop 使用方面的情况,包括大规模集群规模、运行状况及典型问题;
3)国内 Hadoop 服务商在 hadoop 规划、安装部署及集群维护方面的实际经验情况介绍、能力差异及人才储备情况;行业口碑情况。
目标
1、对 Hadoop 产生的背景、发展历程及未来演进方向的了解;
2、对 hadoop 生态圈现状的全面了解;
3、对 Hadoop 关键组件的作用、原理、部署及维护关键点的全面了解;
4、对国内在 Hadoop 研究、使用及人才储备方面的了解;
课程时长
3天(18H)
受众人群
1、了解传统的数据库及数据处理技术;
2、前期参加过与厂家的技术交流,初步了解大数据系统架构、组件的基本功能及大数据应用案例等;
3、缺乏对大数据处理系统的体系化了解,缺乏系统架构设计、组件安装及系统优化维护的实操经验。
分享提纲
| DAY1 | 9:00-10:30 | 为什么会有 Hadoop 传统大规模系统存在的问题 Hadoop 概述 Hadoop 与传统大数据解决方案的比较 Hadoop 生态系统对一种新的解决方案的需求 Hadoop 能解决哪些问题 Hadoop 在云计算和大数据的位置和关系 Hadoop 在国内的发展状况 Hadoop 在国外的发展状况 Hadoop 版本的发展过程和大版本之间的差异 |
| 10:45 - 12:00 | 1、Hadoop 生态系统介绍: 集群管理工具—ambari 分布式存储—HDFS 分布式计算— MapReduce noSQL 数据库—Hbase 工作流工具—Oozie 数据的并行采集—Flume MapReduce 脚本工具—Pig 与关系型数据库之间的数据迁移—Sqoop 资源管理平台—Yarn 数据挖掘算法—Mahout 分布式统一服务—Zookeeper Hadoop 安全工具—Knox 流式计算—Strom 2、Spark 生态系统介绍 内存计算—Spark 实时计算—Spark Streaming SQL on Spark— Spark QL & Shark 基于 spark 的数据挖掘— Mllib 基于 Spark 的图计算—graphx | |
| 13:30 - 15:00 | 大数据的 5 大应用场景 1、 离线计算架构、技术和应用场景 2、 实时查询架构、技术和应用场景 3、 流式计算架构、技术和应用场景 4、 内存计算架构、技术和应用场景 5、 海量数据的 ETL | |
| 15:20 – 17:00 | HDFS:原理、基本结构、副本存放策略 Name Node/Secondary Name Node 及 Date Node 详解; | |
| DAY2 | 09:00 – 12:00 | Map Reduce 工作原理、算法原理及优化思想; Job Tracker 及 Task Tracker 详解 Yarn 原理,与 Hadoop1.0 在功能方面的改善点; |
| 13:30-17:00 | Hbase 的作用、原理、结构; Hive 的作用、原理,与传统数据仓库的相比的优劣势及协作关系; Sqoop 和 Flume 作用、原理; | |
| DAY3 | 09:00 - 10:30 | Storm 的架构、原理和运行模式 Spark 原理、架构及运行模式; Spark 原理;Spark 的架构图; Spark 运行模式介绍 —local;—standalone;—messos;—arn; Spark 的 RDD 什么是 RDD;RDD 的种类;—Tranformation;—ActionSpark 的存储级别;Cache 介绍;Spark 的容错原理 Lineage 容错;Checkpoint 容错;RDD 的创建 |
| 10:45 - 12:00 | 1、Hadoop 集群规划 Hadoop 节点的选型、master 节点和 slave 节点 Hadoop 集群内存要求 Hadoop 集群磁盘分区集群和网络拓扑要求集群软件的端口配置 Hadoop 运维和开源运维工具介绍 Hbase 运维开源运维工具介绍 2、国内在 Hadoop 研究、实际使用及人才储备方面的情况国内企业在 Hadoop 研究方面的参与情况,参与的角色、成果及地位; 国内企事业单位在 Hadoop 使用方面的情况,包括大规模集群规模、运行状况及典型问题; 国内 Hadoop 服务商在 hadoop 规划、安装部署及集群维护方面的实际经验情况介绍、能力差异及人才储备情况;行业口碑情况。 — Hortonworks Hadoop 平台介绍 — Cloudera Hadoop 平台介绍 — MapR Hadoop 平台介绍 常用 Hadoop 平台的优缺点比较 | |
| 13:50 – 17:00 | 1、 银行大数据案例介绍: 客户价值&风险定价 信用风险预测 客户关系管理 客户访问分析 客户流失路径分析 产品购买路径分析 欺诈路径预测 多渠道营销实战 资金链、上下游分析 POS 套现分析 担保圈分析 2、一线互联网大数据案例解析 1)阿里的 ODPS 大数据平台架构介绍 2)阿里的实时推荐架构 3)阿里的交叉营销系统 4)阿里支付宝交易监控系统 4)支付宝微贷案例分析(互联网征信系统) 5)京东打白条系统分析 6)百度预测大数据平台案例分析 7)联通大数据开放平台变现案例分析 3、国内大型银行大数据应用案例 1) 招商银行基于 Hadoop 的数据中心建设 2) 招商银行用户 360°视图建模系统 3) 光大银行大数据风险监控系统 4) 光大银行大数据选址平台 5) 工商银行交易实时监控系统 6)工商银行理财产品交叉营销系统 7) 工商银行 ATM 故障分析预测系统 4、案例实战 1)资金链分析案例实战(数据导入、数据建模、开发、效果展示) 2)银行大数据风险监控系统架构详解 |

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员
Gavin Liu
百林哲咨询(北京)有限公司专家团队成员




 京ICP备2022035414号-1
京ICP备2022035414号-1
