

简介
基于开源大数据技术实训课程,该课程是一个理论与实践相结合的课程,课程只要包含hadoop技术栈的使用和优化、spark技术栈的使用和优化两大块核心内容。
目标
1、帮助学员对Spark、Hadoop生态系统有一个清晰明了的认识;
2、理解Spark、Hadoop系统适用的场景;
3、掌握Spark、Hadoop等初中级应用开发技能;
4、搭建稳定可靠的Spark、Hadoop集群,满足生产环境的标准;
5、了解和清楚大数据应用的几个行业中的经典案例课程时长
课程时长
3天(18H)
受众人群
企业一线的大数据开发人员、大数据平台运维人员、大数据平台优化人员等,具有1-3年左右的大数据基础。
分享提纲
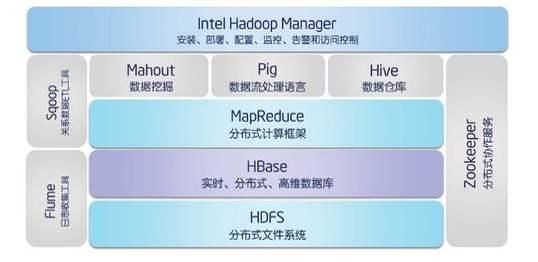
| 第一天 | 一、大数据的整体技术架构 | 1.1开源大数据技术架构 1.2开源大数据常用组件之间的依赖关系 1.3离线计算框架介绍 —Mapreduce、Hive、Tez、Presto、Kylin 1.4实时查询框架介绍 —NoSQL、Hbase 1.5实时计算框架介绍 —Kafka、Spark Streaming、Flink 1.6内存计算框架介绍 —Spark、SparkSQL、SparkMllib、SparkR 1.7前沿大数据技术介绍 —Clickhouse、Drill、Druid、KUDU等 1.8海量日志快速检索架构 —ELK(Elasticsearch、Logstash、Kibana)等 |
二、Hadoop核心组件优化点 | 2.1HDFS架构和原理 2.2HDFS的优化、维护和经常出现的问题 2.3MapReduce架构和原理 2.4MapReduce的优化、维护和经常出现的问题 2.5Yarn的内存、CPU和IO的优化 2.6Hbase的优化和生产环境常见的问题 2.7Hive的优化和Hive的改进工具介绍 2.8Impala、Kylin、Presto工具介绍 2.9RCFile、ORC和parquet格式介绍 | |
三、Hadoop核心组件的运维和配置 | 3.1 HDFS的元数据管理 3.2FSimage和Edit文件解析 3.3手动修改FSimage和Edit文件 3.4HDFS HA的架构运维解析 3.5Yarn服务运维详解 3.6Yarn核心配置参数的详解 3.7Hbase服务运维详解 3.8手动设置Split和Compaction操作 3.9RS宕机的运维处理 3.10Hbase 超大表的优化实践 | |
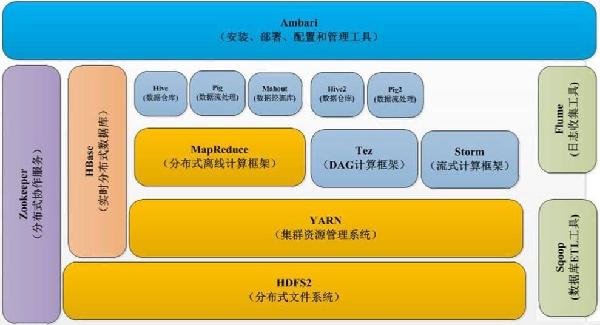
| 第二天 | 四、Yarn实战 | 4.1Yarn架构和原理 4.2ResourceManager工作原理 4.3NodeManager工作原理 4.4ApplicationMaster工作原理 4.5Yarn的资源控制机制 4.6基于内存的控制设置 4.7基于CPU的控制设置 4.8基于IO的控制这是 4.9Yarn为某个运用独立分配资 4.10基于队列的资源管理配置 4.11基于底层硬件的SLA资源配置 4.12不同部门或者用户的资源配置 |
五、Spark Core介绍 | 5.1Spark的编程模型 5.2Spark编程模型解析 5.3Partition实现机制 5.4RDD的特点、操作、依赖关系 5.5Transformation RDD详解 5.6Action RDD详解 5.7Spark的累加器详解 5.8Spark的广播变量详解 5.9Spark容错机制 5.10lineage和checkpoint详解 5.11Spark的运行方式 5.12Spark的Shuffle原理详解 5.13 —Sort-Based原理 5.14—Hash-Based原理 5.15Spark3.0的新特性 5.16Spark DataFrame和DateSet介绍 | |
六、Spark SQL原理和实践 | 6.1Spark SQL原理 6.2Spark SQL的Catalyst优化器 6.3Spark SQL内核 6.4Spark SQL和Hive 6.5DataFrame和DataSet架构 6.6Fataframe、DataSet和Spark SQL的比较 6.7SparkSQL parquet格式实战 6.8Spark SQL的实例和编程 6.9Spark SQL的实例操作demo 6.10Spark SQL的编程 | |
| 第三天 | 七、Spark Streaming原理和实践 | 7.1Structured Streaming架构和原理介绍 7.2Structured Streaming 功能介绍 7.3Structured Streaming 应用场景介绍 7.4Structured Streaming 实时性介绍 7.5Structured Streaming + kafka实战 |
八、Spark Core优化实战 | 8.1小文件优化 8.2文件类型优化 8.3常用算子比较和优化 8.4RDD存储序列化 8.5Spark DAG原理和优化 8.6GC垃圾回收分析 8.7减少任务使用内存 8.8广播大变量 8.9数据本地化 8.10Spark shuffle原理和优化 8.11Spark内存模型设计原理 8.12Spark堆内内存管理 8.13Spark堆外内存管理 8.14Spark任务执行过程分析和资源占用详解 | |
九、Spark 优化实战 | 9.1Spark SQL核心参数优化 9.1.1自定义优化Spark SQL的解析和优化引擎 9.1.2某银行spark任务执行过程分析实践 9.1.3任务优化的步骤 9.1.4通过运行日志和spark任务的Web 9.1.5UI监控查看任务运行慢的原因 9.1.6小文件优化策略 9.1.7文件格式、文件压缩格式的选型 9.1.8shuffle阶段的优化(减少数据量、修改shuffle的参数) 9.1.9数据倾斜的优化策略实战(常用4种解决方案) 9.2Spark主要性能提升参数的实战 9.2.1任务延迟调度的优化(调整资源调度策略) | |
十、大数据案例介绍 | 10.1运营商大数据案例介绍 10.2互联网大数据案例介绍 |
Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员
Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员
Gavin Liu
百林哲咨询(北京)有限公司专家团队成员
Gavin Liu
百林哲咨询(北京)有限公司专家团队成员




 京ICP备2022035414号-1
京ICP备2022035414号-1
