

简介
课程内容:理解大数据和面临大数据带来的挑战,互联网网时代数据已经是公司的成败,对海量
数的存储、计算、分析和挖掘等目前是很多互联网公司的核心,例如广告的推荐、商品推荐等,还可
以挖掘数据来分析用户的潜在价值,面对数据快速的增长,存储和计算变得很重要,课程中我们使用
hadoop来解决海量数据所带来的一些问题,Hadoop目前已经备受互联网的亲耐,hadoop已经成为海
量数据处理必不可少的一个工具,也是最流行的一个海量数据存储和计算的框架,此外还有 hive、Hbase、
sqoop等框架的培训。
学员基础
学员学习本课程应具备下列基础知识:
1)了解 Java或者 python和 shell语言;
2)了解 Linux系统;
目标
Hadoop这门课程从理论到实战再到公司的项目,还有hadoop集群的搭建和性能的调优,再到HDFS
性能的测试和 MapReduce性能的测试再到网络的需求等全面的详解 Hadoop的开发和维护,深刻理解
MapReduce的原理,能过使用 mapreduce进行高级编程,使用 Hive进行数据分析,使用 Hbase进行线
上分析,关系型数据和 HDFS、hive之间的相互迁移,理解 Hadoop的使用场景,面对一个需求适不适
合使用 hadoop。
受众人群
大数据爱好者、程序员、数据分析师,项目经理和对已经使用 hadoop,想提高的用户。
分享提纲
| 第一章 | Hadoop的来源和动机 | ^传统大规模系统存在的问题 ^ Hadoop 概述 ^ Hadoop分布式文件系统 ^ MapReduce工作原理 ^ Hadoop集群剖析 ^ Hadoop生态系统对一种新的解决方案 的需求 ^ Hadoop的行业应用案例分析 ^ Hadoop在云计算和大数据的位置和关 系 | 数据开放,数据云服务平台 (DAAS)时代今Hadoop平台在数据云平台 (DAAS)上的天然优势 今数据云平台(DAAS平台)组成部分今互联网公共数据大云(DAAS)案例 今 Hadoop构建构建游戏云(Web Game Daas)平台 |
| 第二章 | Hadoop集群规划 | ^ Hadoop集群内存要求 > Namenode的机器配置 > Datanode的机器配置 > SNN的机器配置 ^ Hadoop集群磁盘分区 ^ 集群和网络拓扑要求 ,集群软件的端口配置 | 今针对 NameNode Jobtracker DataNode TaskTracker Hiveserver等不同组件需求推荐服务器配置 |
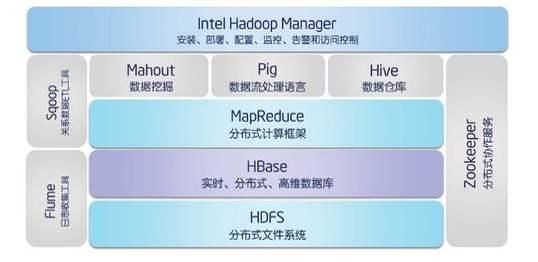
Hadoop简介和生态系统介绍 | ^传统大规模数据分析存在的问题 ^ Hadoop 概述 ^ Hadoop与分布式文件系统 ^ Hadoop生态系统 ^ Hadoop的行业应用案例分析 ^ Hadoop在云计算和大数据的位置和关 系 ^ Hadoop版本介绍 ^ Hadoop 与 Google FS 的关系 ^ Hadoop在国内的使用情况和未来 | > Hadoop在推荐领域的使用案例介 绍 | |
| 第三章 | Hadoop安装和主要配置文件介绍 | ^ Hadoop安装所需软件介绍 ^ Hadoop单机安装 ^ Hadoop伪分布式安装 ^ Hadoop完全分布式安装 ,Hadoop三个节点安装的配置介绍 ^ Hahoop多节点ssh配置 ^ Hadoop格式化详解 ^ Hadoop核心配置文件介绍 ^ 核心配置文件core-site.xml ^ HDFS 配置文件 hdfs-site.xml ^ Mapreduce 配置文件 mapred-site.xml ^ master文件配置详解 ^ slave文件配置详解 ,Hadoop启动和停止方法一 —start-all.sh 详解 —stop-all.sh 详解 ,Hadoop的启动和停止方法二 —hadoop-deamon.sh 详角¥,Hadoop安装的常见错误介绍和解决方案 ^ 使用自带的wordcount和pi测试集群安装是否成功 ^ 使用Streaming来测试集群安装是否成 功 | > Hadoop单机演示 > Hadoop伪分布式演示 > Hadoop完全分布式演示 > Hadoop两种启动方式的演示 > Hadoop安装常见错误的介绍和演示 > Hadoop 自带的wordcount和pi演示 > Hadoop Streaming 的案例演示 |
| 第四章 | Hadoop组件介绍 | ^ Hadoop NameNode 介绍 Z Hadoop SecondaryNameNode 介绍 Hadoop DataNode 介绍 Hadoop JobTracker 介绍 Hadoop TaskTracker 介绍 | |
| 第五章 | Hadoop的HDFS模块 | HDFS架构介绍 HDFS原理介绍 NameNode功能详解 DataNode功能详解 SecondaryNameNode 功能详解 HSFD 的 fsimage 和 editslog 详解 HDFS的block详解 HDFS的block的备份策略 Hadoop的机架感知配置 HDFS的shell命令介绍 HDFS 的 thrift server 服务介绍 HDFS的API接口介绍 HDFS的权限详解 Hadoop的客服端接入案例 | >Hadoop的shell命令演示 >Hadoop的API接口演示 >Hadoop的客服端接入案例 |
| 第六章 | MapReduc er入门和 高级开发 实战 | Mapreduce 原理 MapReduce 流程 剖析一个MapReduce程序 Mapper和Reducer抽象类详解 Mapreduce的最小驱动类 MapReduce自带的类型 自定义Writables和WritableComparables Mapreduce 的输入 InputFormats MapReduce 的输出 OutputFormats 自定义 InputFormat 自定义 InputSPlits 自定义 RecorderReader Combiner 详解 Partitioner 详解 DistributeFileSystem 详解 Hadoop Tools工具介绍 Counter计数器详解 自定义Counter计数器 基于Hadoop二次开发实战 MapReduce的优化 Map和Reduce的个数设置 ^ Hadoop小文件优化 ^ 任务调度 ^默认的任务调度 ^ 公平任务调度 ^ 能力任务调度 ^ 使用 Hadoop MapReduce Streaming 编程 MapReduce的单兀测试 | >MapReduce实现海量数据比较大小案例 >自定义Hadoop类型案例 >自定义Partitioner案例 >实现在内存随机生成100个数,分成两个Map来比较大小 >自定义 inputFormat 和 InputSplit和 RecorderReader 来实现 MapReduce读取Redis里面的数据。 >多文件输出和自动定义MapReduce的输出名 >MapReduce实现Join算法案例 >MapReduce实现海量文档相似度算法 >自定义Counter案例实现 >MapReduce 实现 Pangrank 算法。 >MapReduce单兀测试:Map的单兀测试测试、reduce单兀测试和 MapReduce整体的单兀测试实战。 >某公司使用MapReduce分析日志案例(10T数据以上) > MapReducer日志连续性验证 > MapReduce加密解密 > MapReduce索引倒排 > 配置公平调度器案例实战 |
| 第七章 | Hive的使用和实战 | Hive和Pig基础 ^ Hive、Impala 和 presto 的比较 Hive的作用和原理说明 ^ Hadoop仓库和传统数据仓库的协作关系 ^ Hadoop/Hive仓库数据数据流 ,Hive部署和安装 ,Hive Cli的基本用法 ^ Hive的server启动 ^ HQL基本语法,Hive的加载数据本地加载和HDFS加 载 ^ Hive的partition详解 ^ Hive的存储方式详解,RCFILE、TEXTFILE 和 SEQUEUEFILE 夂 Hive的UDF和UDAF ^ Hive的transform 详解,Hive的JDBC连接 | > 使用JDBC连接Hive进行查询和 分析 > 使用正则表达式加载数据 > 编写UDF函数 > 编写UDAF自定义函数 > Partition使用实战 > Transform使用实战 > 某些大型公司使用hive分析日志 案例详解和实战。 |
| 第八章 | Hbase 使 用 | ^ Hbase原理 ^ Hmaster 详角¥ ^ RegionServer详角¥ ^ Zookeeper 介绍 ^ Hbase安装 ^ Hbase逻辑视图介绍 ^ Hbase物理视图介绍 ,Hbase的二级索引介绍 ,Hbase 的 DDL 和 DML ^ Hbase表的设计案例 ^ Hbase的import功能介 ^ MapReduce 操作 Hbase Hbase 的 thrift Server 介绍 Hbase的API介绍 Hbase案例分析 | > Hbase安装实战 > MapReduce 操作 Hbase 实战 > Hbase的API实战 > Hbase表结构设计实战 > Hbase+OpenTSDB 实战 |
| 第九章 | Hadoop 安 全和性能 优化 | Hadoop的可伸缩性应用 Hadoop的线性伸缩性 Hadoop的最佳实战 Map/Reduce性能测试 HDFS的性能测试 Hadoop企业级架构 Hadoop的安全实战 Hadoop的运维知识总结 | 实战: MapReduce性能测试案例实战,找出 mapreduce的瓶颈和优化的参数 |
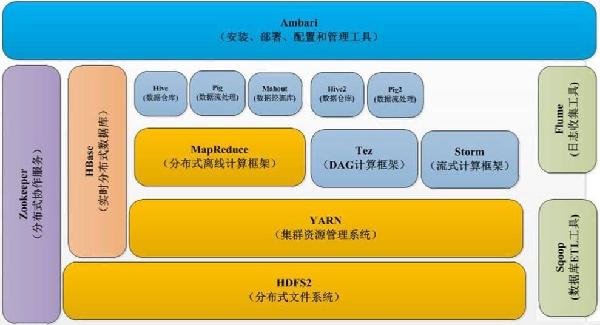
| 第十章 | Hadoop 集 群配置介 绍和维护 | Hadoop集群的部署要点 NameNode 和 SecondaryNameNode 和 JobTracker机器的配置要求 dataNode与tasktracker机器的配置要求Hadoop集群管理的工具介绍 Ganglia和nigos监控Hadoop集群介绍 Ambri介绍 添加和删除节点演示 Namenode的单点解决方案 NameNode的NFS备份介绍 集群所有dataNode挂掉的故障介绍 集群NameNode的fsimage丢掉恢复方法 Hadoop集群维护的注意点 | |
| 第十一章 | Sqoop 介 绍 | ^ Sqoop是什么 ^ Sqoop安装 ,Sqoop把mysql数据导入HDFS ,Sqoop把HDFS数据导入Mysql ^ Sqoop吧Mysql数据导入Hive ^ Sqoop吧Mysql数据导入Hive分区 | 今 Mysql、HDFS和HIVE之间数据 转换的演示 |

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员
Gavin Liu
百林哲咨询(北京)有限公司专家团队成员
Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员




 京ICP备2022035414号-1
京ICP备2022035414号-1
