

课程简介
当下是大数据时代,为构建大数据平台,技术人员需要对分布式计算平台有一定深入的理解和应用。MapReduce作为一个经典的分布式计算框架,已经广为人知,且得到了广泛的应用,但MapReduce自身存在很多问题,包括迭代式计算和DAG计算等类型的数据挖掘与机器学习算法性能低下,不能很好地利用内存资源,编程复杂度较高等。为了克服MapReduce的众多问题,新型计算框架出现了。
课程收益
本课程将为大家全面而又深入的介绍Spark、Hadoop平台的构建流程,涉及Spark、Hadoop系统基础知识,概念及架构, Spark、Hadoop实战技巧,Spark、Hadoop经典案例等。
通过本课程实践,帮助学员对Spark、Hadoop生态系统有一个清晰明了的认识;理解Spark、Hadoop系统适用的场景;掌握Spark、Hadoop等初中级应用开发技能;搭建稳定可靠的Spark、Hadoop集群,满足生产环境的标准;了解和清楚大数据应用的几个行业中的经典案例,包括阿里巴巴,华为等。
受众人群
各类 IT/软件企业和研发机构的软件架构师、软件设计师、程序员。对于怀有设计疑问和问题,需要梳理解答的团队和个人,效果最佳。了解Linux系统及相关语言环境。
课程周期
3天
课程大纲
标题 | 授课内容 |
大数据在 国外的运用(第一天) | l 大数据在国外的发展情况 l 大数据在国外的应用 l Hadoop在国外的使用 l 大数据在金融业的使用案例 l 大数据的发展与展望 |
大数据在国内的运用(第一天) | l 大数据在国内的使用介绍 l 离线计算框架介绍 l 流式计算框架介绍 l 内存计算框架介绍 l 内存流式计算介绍 l 大数据实时请求框架介绍 l 大数据在证券的案例介绍 l 大数据在银行的案例介绍 |
大数据生态系统介绍(第一天)
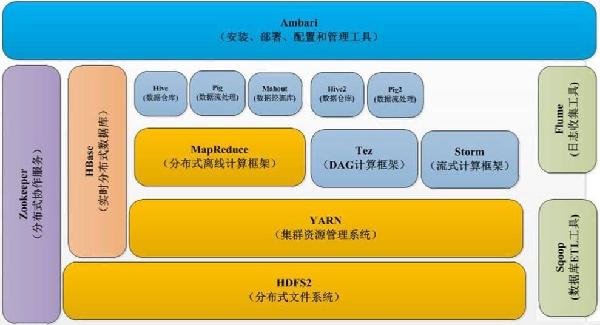
| l 分布式存储—HDFS l 分布式并行计算—MapReduce l 基于Hadoop的数据仓库—Hive l 集群管理工具—ambari l 工作流工具—Oozie l 数据的并行采集—Flume l MapReduce脚本工具—Pig l 与关系型数据库之间的数据迁移—Sqoop l 资源管理平台—Yarn l 数据挖掘算法—Mahout l 分布式统一服务—Zookeeper l Hadoop安全工具—Knox l 流式计算框架—Storm l 内存计算框架—Spark l 数据挖掘框架—Mahout、Mllib和Graphx |
Hadoop核心组件详解(第一天) | l HDFS 基本结构 l HDFS 副本存放策略 l NameNode 详解 l SecondaryNameNode 详解 l HA的架构和原理 l DataNode 详解 l MapReduce并行计算架构 l JobTracker 详解 l TaskTracker 详解 l Yarn原理详解 l Resourcemanger详解 l Nodemanager详解 l ApplicationMaster详解 |
Hadoop的HDFS模块(第一天) | l HDFS架构介绍 l HDFS原理介绍 l NameNode功能详解 l DataNode功能详解 l SecondaryNameNode功能详解 l HSFD的fsimage和editslog详解 l HDFS的block详解 l HDFS的block的备份策略 l Hadoop的机架感知配置 l HDFS的shell命令介绍 l HDFS的thrift server服务介绍 l HDFS的API接口介绍 l HDFS的权限详解 l Hadoop的客服端接入案例
n Hadoop的shell命令演示 n Hadoop的API接口演示 n Hadoop的客服端接入案例 |
MapReducer入门(第二天) | l Mapreduce原理 l MapReduce流程 l 剖析一个MapReduce程序 l Mapper和Reducer抽象类详解 l Mapreduce的最小驱动类 l MapReduce自带的类型 l Combiner详解 l Partitioner详解 l DistributeFileSystem详解 l Hadoop Tools工具介绍 l Counter计数器详解 l 自定义Counter计数器 l 基于Hadoop二次开发实战 l MapReduce的优化 l Map和Reduce的个数设置 l Hadoop小文件优化 l 任务调度 l 默认的任务调度 l 公平任务调度 l 能力任务调度 l 使用 Hadoop MapReduce Streaming 编程 l MapReduce的单元测试
n 实现在内存随机生成100个数,分成两个Map来比较大小 n 多文件输出和自动定义MapReduce的输出名 n MapReduce实现Join算法案例 n MapReduce实现海量文档相似度算法 n 自定义Counter案例实现 n MapReduce实现Pangrank算法。 n MapReduce单元测试:Map的单元测试测试、reduce单元测试和MapReduce整体的单元测试实战。 n 某公司使用MapReduce分析日志案例(10T数据以上) n 配置公平调度器案例实战
|
Yarn实战(第二天) | l Yarn架构和原理 l ResourceManager工作原理 l NodeManager工作原理 l ApplicationMaster工作原理 l Yarn的资源控制机制 l 基于内存的控制设置 l 基于CPU的控制设置 l 基于Yarn的程序开发步骤 l Yarn为某个运用独立分配资源 l Yarn与Messos的区别
n 基于Yarn资源控制实战 n 基于Yarn的程序开发实战 n MapReduce on Yarn实战 n Hbase on Yarn 实战 |
Hive、impala和Tez实战 | l Hive和Pig基础 l Hive、Impala和presto的比较 l Hive的作用和原理说明 l Hadoop仓库和传统数据仓库的协作关系 l Hadoop/Hive仓库数据数据流 l Hive 部署和安装 l Hive Cli 的基本用法 l Hive的server启动 l HQL基本语法 l Hive的加载数据本地加载和HDFS加载 l Hive的partition详解 l Hive的存储方式详解 l RCFILE、TEXTFILE和SEQUEUEFILE l Hive的UDF和UDAF l Hive的transform详解 l Hive的JDBC连接 l Impala实战 l Tez实战 |
Hbase使用(第三天) | l Hbase原理 l Hmaster详解 l RegionServer详解 l Zookeeper介绍 l Hbase安装 l Hbase逻辑视图介绍 l Hbase物理视图介绍 l Hbase的二级索引介绍 l Hbase 的DDL和DML l Hbase表的设计案例 l Hbase的import功能介绍 l MapReduce操作Hbase l Hbase的 thrift Server介绍 l Hbase 的API介绍 l Hbase使用场景介绍 l Hbase案例分析
n MapReduce操作Hbase实战 n Hbase的API实战 n Hbase表结构设计实战 n 银行信用卡刷卡记录的查询 |
互联网大数案例分享(第三天) | l 淘宝大数据平台深度解析 l 基于大数据平台的实时营销架构 l 淘宝大数据推荐架构介绍 l 大数据实时分析架构 |
某城商行大数据案例(第三天) | l 大数据架构详解 l POS商户的分析和交易流水分析 架构:Hadoop+Hive+Hbase+Storm l 交易风险预测和实时营销 架构: Hadoop+Flume+Storm+ l Redis+Esper+Hbase |
某国字头银行大数据案例(第三天) | l 大数据架构详解 l 基于Hadoop的数据仓库 架构:Hadoop+Hive+Hcatalog+oozie l 担保圈分析、资金链上下游分析 架构:Hadoop+Spark Graphx+Mllib+R l 网址选择 架构:Hadoop+Hive+高德地图 |

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员
Gavin Liu
百林哲咨询(北京)有限公司专家团队成员
Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员
Gavin Liu
百林哲咨询(北京)有限公司专家团队成员

Gavin Liu
百林哲咨询(北京)有限公司专家团队成员




 京ICP备2022035414号-1
京ICP备2022035414号-1
